Latent Semantic Space model for Word Representations
Recent work has shown that words could be efficiently mapped into continuous vector space that preserves important semantic relationships we usually observe in natural languages. For example, if we consider vector representation of the word “King”, subtract vector of the word “Man” from it and then add “Woman” to the result, the closest word in the vector space would be “Queen”. Moreover, such mapping could be learned from unstructured text data by a family of shallow neural models, very simple comparing to its deep predecessors and thus allowing to be trained at a very large scale.
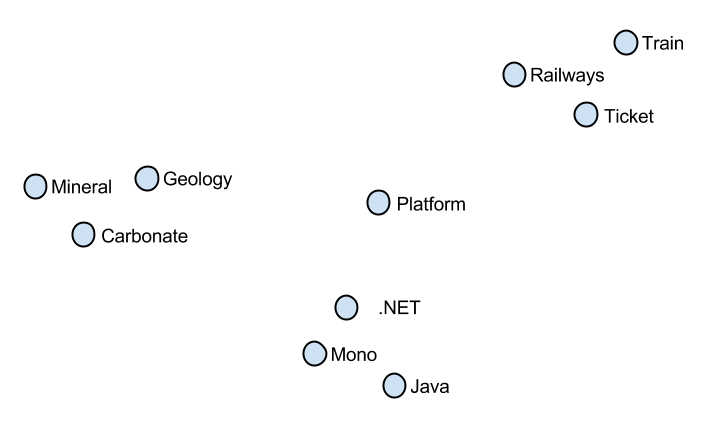
While such a property of word vectors is interesting itself, they could be used in a number of natural language processing tasks including classification and informational retrieval. Recent studies also apply word vectors to the task of machine translation where additional mapping between semantic spaces of different languages is also being learned.
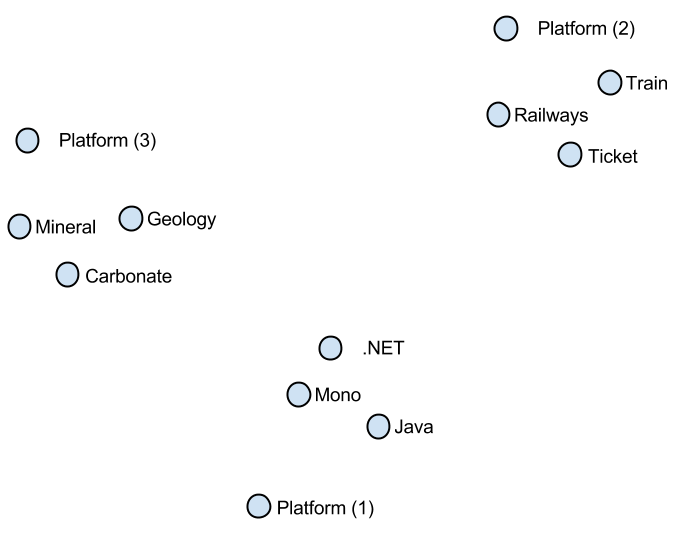
In this project we extend and generalize existing approaches to learning word vectors in order to capture the fundamental property of words to have several different meanings also known as polysemy. It was well studied how accounting for words ambiguity could improve the quality of NLP system and thus modelling this property is very important for applications. Our model jointly learns individual vectors for different meanings of words and performs word sense disambiguation by inferring probabilities of word instances in the text belong to certain meanings.
Have you spotted a typo?
Highlight it, click Ctrl+Enter and send us a message. Thank you for your help!
To be used only for spelling or punctuation mistakes.