
Способы визуализации текстовой информации
Существует два понимания понятия “визуализация текстов”. В первом понимании, визуализация текстов – это генерация изображений по входному тексту. В [1] приводится такой пример: по тексту, представленному на Рис. 1 требуется построить изображение. При этом, система, генерирующая изображение, должна понимать, что компьютер может стоять только на столе и автоматически добавлять стол на изображение. Среди русскоязычных работ этого направления отметим работу [2]. Рис. 1
Рис. 1
Другое понимание понятие “визуализация текстов” предполагает изображение либо элементов текста, либо структур, извлеченных из текста, для образовательных или аналитических нужд. В этом понимании можно выделить несколько различных подходов.
Исторически первый – так называемое облако тегов (tag cloud). Облако тегов представляет собой множество ключевых слов или словосочетаний – тегов, извлеченных из текста, изображенных на плоскости. Размер каждого тега зависит от частоты или любой другой частотной характеристики тега. Облако тегов может иметь любую форму: действительно облака или, например, звездочки.
Рис. 2, источник: https://uniqons.wordpress.com
Иногда цветом на облаке тегов отмечают какие-нибудь важные характеристики, например, авторство. На Рис. 3 голубым отображены слова из предвыборной программы Обамы, коричневым – Маккейна. Облака тегов позволяют получить общее представление о содержании текста или коллекции текстов. Например, в [4] облака тегов используются для визуализации частых слов в позитивных или негативных твитах, посвященных предвыборной кампании 2012 г. в США. Одно из развитий идеи облака тегов представлено в [5]: облака Вена, которые используются для демонстрации контраста между двумя коллекциями текстов. 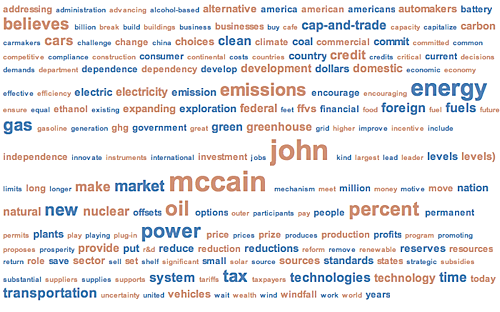
Рис. 3, источник: http://www.planetizen.com/
Рис. 4, Три примера облаков Вена. В левой части частые слова из твитов, содержащих слово “Orioles” (бейсбольная команда), в правой – “Nationals”. По середине расположены общие для обеих коллекций слова.
Второй подход к визуализации текстов – это визуализация элементов текстов и теоретико-множественных, алгебраических или статистических отношений между ними. Как правило, в рамках этого подхода текст или коллекция текстов представляется графом, в котором вершины – ключевые слова или словосочетания или понятия, выделенные из текстов, соединенные ребрами по каким-то принципам. Например, в [6] составляется панорама тем – графом из трех соединенных компонент (см. Рис. 5), каждая доля соответствует одному источнику, узлы подписаны ключевыми словами или словосочетаниям. В графе есть два типа ребер: внутри одной компоненты, соответствующей одному источнику, узлы соединены в соответствии с взаимной встречаемостью. Второй тип ребер соединяет похожие узлы из разных источников. В [7] строится карта метро (Рис. 6) – визуализация динамических кластеров ключевых слов и словосочетаний.
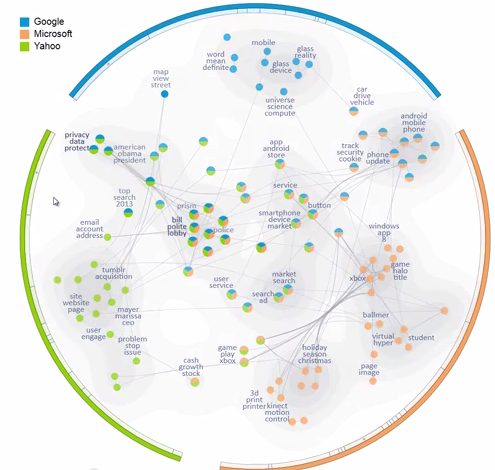 Рис. 5 | 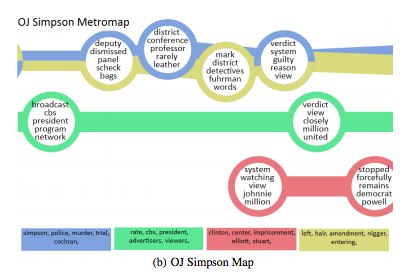 Рис. 6 |
Третий подход к визуализации текстов – это визуализация моделей скрытых тем (latent topics). Система Serendip [8] выделяет скрытые темы в тексте и подсвечивает слова во входном тексте цветом (Рис. 7). У каждой скрытой темы свой цвет, интенсивность цвета зависит от степени вхождения слова в тему. В [9] скрытые темы представлены в виде облаков тегов (Рис. 8).
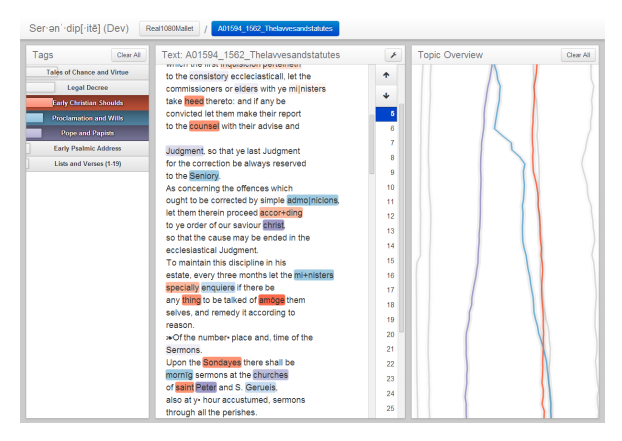
Рис. 7 |
Рис. 8 |

Наша работа по построению графа референций принадлежит ко второму подходу. В графе референций узлы – это ключевые слова или словосочетания, а направленные ребра вида A->B задают отношение вида “если встречается A, то встречается B”, то есть, “B встречается в контексте A”.
- Chang, Angel X., Manolis Savva, and Christopher D. Manning. "Semantic parsing for text to 3d scene generation." ACL 2014 (2014): 17.
- Усталов, Дмитрий, и Александр Кудрявцев. "Применение онтологии при синтезе изображения по тексту." Доклады всероссийской научно–практической конференции Анализ Изображений, Сетей и Текстов. М.: Национальный Открытый Университет ИНТУИТ. 2012
- Coupland D. (1996), Microserfs, Flamingo
- Wang, H., Can, D., Kazemzadeh, A., Bar, F., & Narayanan, S. (2012, July). A system for real-time twitter sentiment analysis of 2012 us presidential election cycle. In Proceedings of the ACL 2012 System Demonstrations (pp. 115-120). Association for Computational Linguistics.
- Coppersmith, G., & Kelly, E. (2014). Dynamic Wordclouds and Vennclouds for Exploratory Data Analysis. Sponsor: Idibon, 22.
- Liu, S., Wang, X., Chen, J., Zhu, J., & Guo, B. (2014, October). TopicPanorama: A full picture of relevant topics. In Visual Analytics Science and Technology (VAST), 2014 IEEE Conference on (pp. 183-192). IEEE.
- Shahaf, D., Yang, J., Suen, C., Jacobs, J., Wang, H., & Leskovec, J. (2013, August). Information cartography: creating zoomable, large-scale maps of information. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1097-1105). ACM.
- Alexander, E., Kohlmann, J., Valenza, R., Witmore, M., & Gleicher, M. (2014, October). Serendip: Topic model-driven visual exploration of text corpora. In Visual Analytics Science and Technology (VAST), 2014 IEEE Conference on (pp. 173-182). IEEE.
- Smith, A., Chuang, J., Hu, Y., Boyd-Graber, J., & Findlater, L. (2014). Concurrent Visualization of Relationships between Words and Topics in Topic Models. Sponsor: Idibon, 79.
![]()
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.