Открывая мир ИИ: Институт искусственного интеллекта и цифровых наук запускает научный семинар
.png "Открывая мир ИИ: Институт искусственного интеллекта и цифровых наук запускает научный семинар")
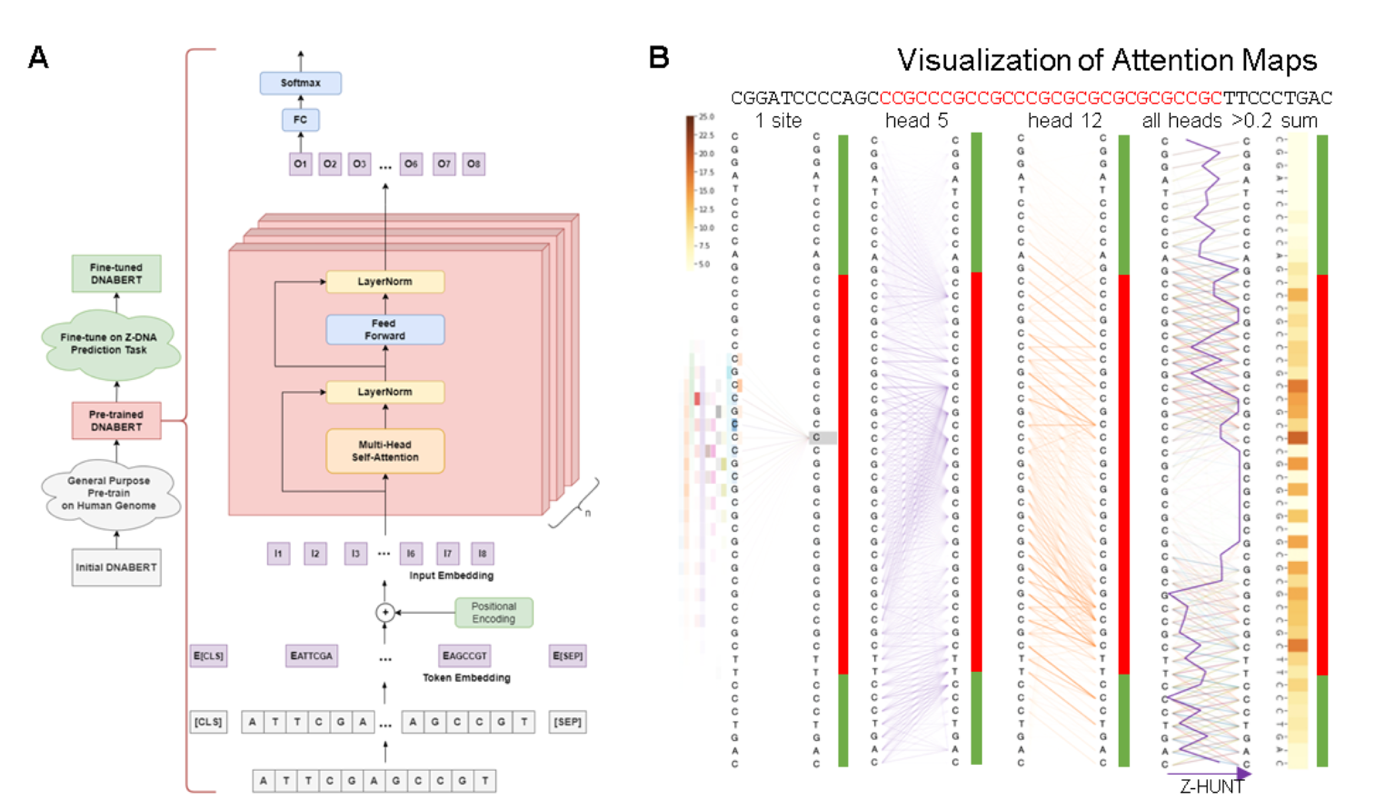
В ДНК последовательности генома закодировано огромное количество информации, необходимой для работы генетического компьютера. Подобно моделям естественного языка, в геномике создаются базовые модели для изучения обобщаемых представлений на основе немаркированных данных генома, которые затем можно до-обучать до конкретных задач, например, для нахождения функциональных геномных элементов. Из-за квадратичного масштабирования внимания предыдущие геномные модели на основе архитектуры трансформериспользовали в качестве контекста от 512 до 4 000 токенов, что значительно ограничивало моделирование дальних взаимодействий в ДНК.
В ноябре 2023 года ученые из Стэнфордского, Гарвардского и Монреальского университетов опубликовали модель HyenaDNA, с длиной контекста до 1 миллиона токенов на уровне одного нуклеотида, что позволило получить увеличение до 500 раз по сравнению с предыдущими моделями, основанными на плотном внимании. HyenaDNA субквадратично масштабируется по длине последовательности (обучается в 160 раз быстрее, чем трансформер), использует однонуклеотидные токены и полный глобальный контекст на каждом слое.
Попцова Мария Сергеевна
Международная лаборатория биоинформатики: Заведующий лабораторией
На семинаре мы разберем детали реализации DNABERT, GENA-LM (AIRI) и HyenaDNA, а также обсудим их приложения для решения задач геномики.
2 апреля 2024 г., 18:00
г. Москва, Покровский бульвар, д. 11
Попцова Мария Сергеевна
Международная лаборатория биоинформатики: Заведующий лабораторией