

Стратегические последствия текстовых дипфейков для консалтинга и аналитики
27 ноября 2020 года состоялось открытое заседание «Стратегические последствия текстовых дипфейков для консалтинга и аналитики» в рамках семинара «Трансдисциплинарные приложения наук о данных» МЛ ИССА
{kind=link}
{kind=link}
{kind=link}
Илья Кузьминов, кандидат наук, ведущий научный сотрудник, Директор центра стратегической аналитики и больших данных Института статистических исследований и экономики знаний выступил с докладом «Стратегические последствия текстовых дипфейков для консалтинга и аналитики».
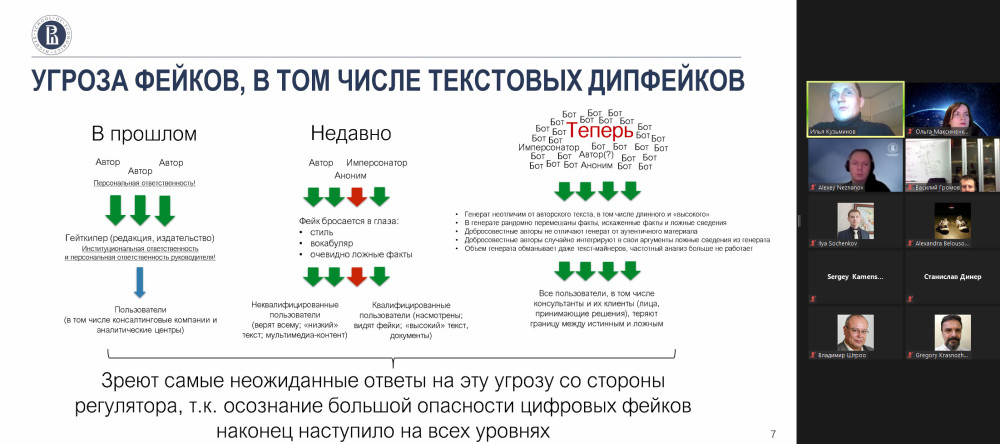
Аннотация: Обсуждается революция в обработке естественного языка 2018-2020 годов, появление принципиально нового класса предобученных генеративных языковых моделей, их опасность как инструментов массированной генерации длинных и структурно сложных текстовых дипфейков, имитирующих тексты высокого образовательного ценза, такие как фактографические справки ученых и экспертов и аналитические доклады исследовательских центров, и вытекающие из новых технических возможностей риски для традиционной аналитики и консалтинга. Показана трансформация институциональной среды распространения информации, угасание роли традиционных гейткиперов, и связанный с ними подрыв доверия к любым утверждениям и снижение доступности истины. Рассмотрены механизмы информационной перегрузки и оппортунистического поведения игроков в сфере аналитики, которые приведут к изменению рынка, функций и роли аналитики и консалтинга в современном обществе под давлением опасности фейков. Показана особая роль стратегической аналитики. Предлагаются организационно-технические методы борьбы с текстовыми дипфейками в науке, образовании и консалтинге, включая рынок автоматического детектирования как синтетических, так и, в более общем случае, некондиционных текстов в этих сферах. Рассматриваются ожидаемые направления реакции, часто непропорциональной, регулятора на угрозы, формируемые растущей доступностью дипфейков.
Запись семинара доступна по адресу https://www.youtube.com/watch?v=oaR9U-dA5Fc .
Отметим следующие комментарии.
Илья Соченков, к.ф.-м.н., заместитель директора центра стратегической аналитики и больших данных, ИСИЭЗ НИУ ВШЭ (1:25:00).
«Никаких революций в NLP не произошло: основы дистрибутивной семантики, заложенные в фундаментальных работах второй половины XX-го века, получили развитие в конце 90-х годов, а их широкое применение связано с реализацией библиотек машинного обучения (Word2Vec и наследников). В дальнейшем развитие глубокого машинного обучения позволило строить более сложные end-to-end модели в области NLP (например, чат-боты). Мы пришли к эпохе «машинного творчества», когда компьютерные модели смогли генерировать уникальные тексты. Эта возможность таит в себе опасности злоупотребления в части генерации фейковых новостей, текстов, подталкивающих людей совершать определённые действия с целью влияния на индивидуумов в обществе посредством социальных сетей. Поэтому возрастает важность области исследования выявления сгенерированных текстов. Эта задача близка по своей сути к задаче выявления fake-news. Эффективное применение генеративных моделей требует развития методов уменьшения признаковых пространств («сжатия моделей»), а также оптимизации инструментов поиска ближайшего соседа в пространствах векторов, содержащих в наборах миллиарды точек.»
Василий Громов, д.ф.-м.н., старший научный сотрудник МЛ интеллектуальных систем и структурного анализа, ФКН НИУ ВШЭ:
«Действительно, рост deepfake'ов представляет собой вызов самым глубоким основам нашего социума, самому понятию социальности, вызов в понимании Тойнби. Но, собственно говоря, у Тойнби и приводится последовательность реакций любого социума на вызов. Попытка не замечать очевидного, попытка запретить, творческий ответ, позволяющий преодолеть вызов. Мы сейчас как раз пришли ко второму этапу, и поэтому наша задача на сосредотачиваться на деталях второго этапа, но пытаться понять, каким будет третий, каким будет творческий ответ. Здесь уместно упомянуть проект Поймай бота: обратная задача обработки естественных языков (Spot the bot: the inverse problem of NLP, руководитель проф. Громов В.А.), который осуществляется в МЛ ИССА. В рамках проекта предлагается выявлять наиболее существенные характеристики, отличающие тексты, сгенерированные ботами, от текстов, написанных людьми. Предлагаем всем желающим присоединяться к проекту и создавать вокруг него сетевую структуру (сетевую лабораторию). Любая Ваша помощь нужна нам.»
Алексей Незнанов, к.т.н., старший научный сотрудник МЛ интеллектуальных систем и структурного анализа, ФКН НИУ ВШЭ:
«Креативность решений ИИ, основанных на достижениях в состязательных/генеративных моделях (GAN) и универсальных векторных языковых моделях (начиная с революции трансформеров — PostBERT-эпоха), стала настолько высокой и настолько внезапно, что стандартный дискурс этики ИИ взорвался. Последствия нам только предстоит осмыслить. Данный семинар выпукло показал как значимость (с акцентом на негативные последствия), так и актуальность некоторых направлений исследований. Особо выделю исследования в области интерпретируемости, надёжности и сертифицируемости решений ИИ одновременно с кибербезопасностью интеллектуальных систем. Надеюсь, что позитивных последствий в итоге будет больше, чем негативных.»