Разработка метода оценки сходства датасетов
Выполнил: Копылов Олег Иванович
В настоящее время существует большое число доступных открытых датасетов. Но еще большее число датасетов закрытых, которые существуют в рамках отдельных компаний. Не всегда легко понять, какие из существующих языковых моделей подойдут для конкретного закрытого датасета. Например, в случае, если обучаться на закрытом датасете невозможно или нецелесообразно.
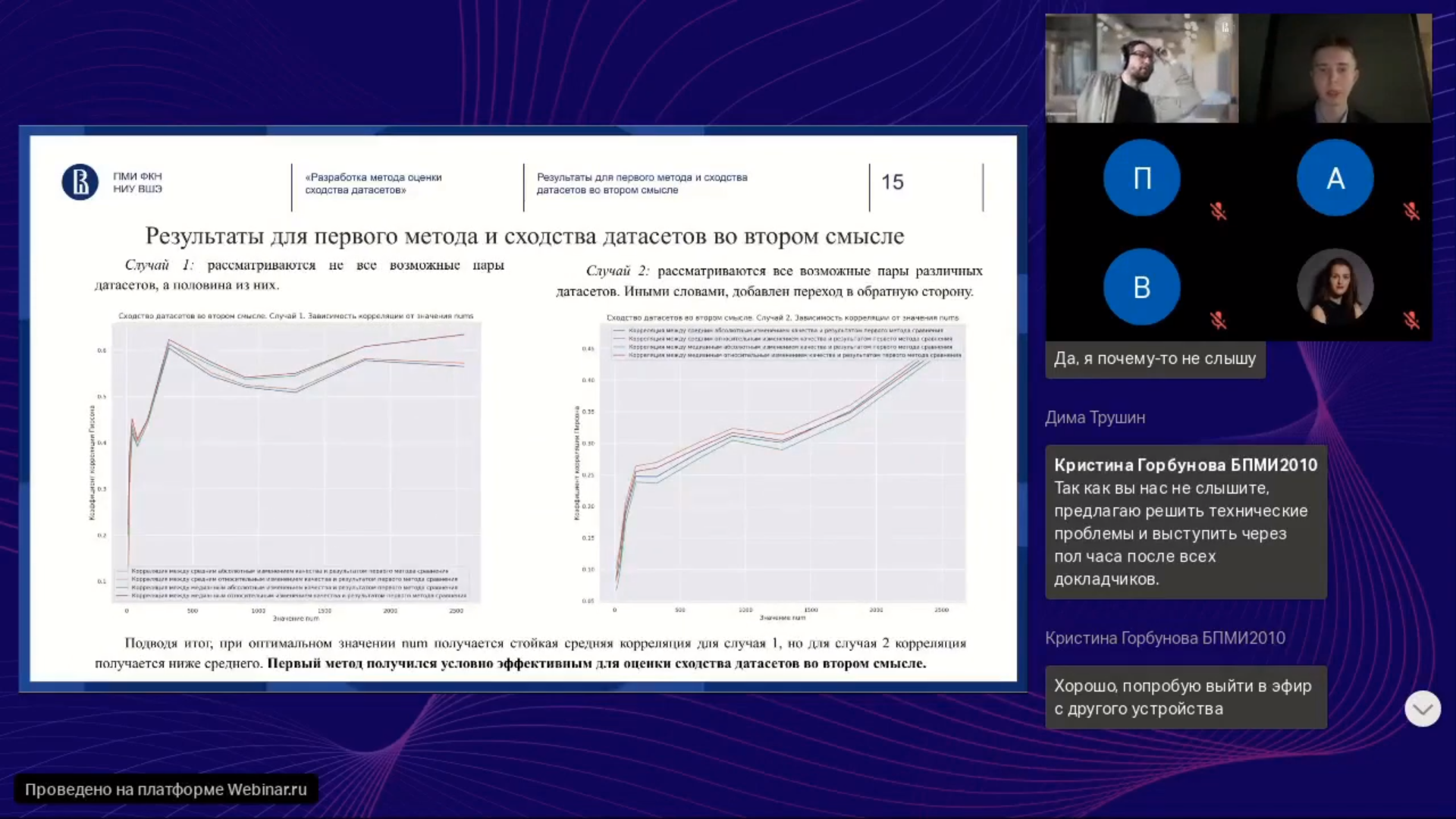
В рамках курсовой работы будет разработан метод, который помогает справиться с этой проблемой. Это метод оценки сходства датасетов. При условии сходства датасетов А и B, модель, эффективно работающая на датасете A, также эффективно работает и на датасете B. Метод оценки сходства датасетов представляет собой функцию, которая принимает два датасета и возвращает численное значение, коррелирующее с изменением качества при переходе с одного датасета на другой. Таким образом, если открытый датасет А схож с закрытым датасетом В, и проверена эффективность модели на открытом датасете А, то эта модель эффективно работает и на закрытом датасете В.
Предполагается, что датасеты являются текстовыми, рассматривается задача бинарной классификации. Проведено две серии экспериментов, первая серия относится к определению положительности или негативности отзыва, вторая серия – к классификации содержимого сообщений или электронных писем как спам и не спам. В каждой серии экспериментов рассмотрено два датасета и 10 языковых моделей.
Архив с материалами (Копылов)
- В архиве содержатся отчет и презентация
Ссылка на репозиторий на GitHub
Руководитель проекта

![]()
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.