
Десять статей исследователей ФКН приняты на конференцию NeurIPS 2021
![]()
35-ая конференция NeurIPS 2021 (Conference on Neural Information Processing Systems) — одна из крупнейших в мире конференций по машинному обучению и нейронным сетям, которая проводится с 1989 года. В 2021 году конференция проходит онлайн 6-14 декабря.
В этом году на NeurIPS были приняты десять статей исследователей ФКН:
-
On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay (Екатерина Лобачева, Максим Кодрян, Надежда Чиркова, Андрей Малинин, Дмитрий Ветров);
-
Leveraging Recursive Gumbel-Max Trick for Approximate Inference in Combinatorial Spaces (Кирилл Струминский, Артем Гадецкий, Денис Ракитин, Д. Карпушкин, Дмитрий Ветров);
-
Distributed Saddle-Point Problems Under Similarity (Александр Безносиков, Дж. Скутари, Александр Рогозин, Александр Гасников);
-
Lower Bounds and Optimal Algorithms for Smooth and Strongly Convex Decentralized Optimization Over Time-Varying Networks (Д. Ковалев, Э. Гасанов, П. Ричтарик, Александр Гасников);
-
Moshpit SGD: Communication-Efficient Decentralized Training on Heterogeneous Unreliable Devices (Максим Рябинин, Эдуард Горбунов, Всеволод Плохотнюк, Г. Пехименко);
-
Tight High Probability Bounds for Linear Stochastic Approximation with Fixed Stepsize (А. Дюрмю, Эрик Мулин, Алексей Наумов, Сергей Самсонов, К. Симен, Х.-Т. Вай);
-
Distributed Deep Learning in Open Collaborations (Михаил Дискин, А. Бухтяров, Максим Рябинин, Л. Сольньер, К. Лоест, Антон Синицин, Дмитрий Попов, Дмитрий Пыркин, Максим Каширин, Александр Борзунов, А. Вилланова дель Морал, Д. Мазур, Я. Жернит, Т. Вульф, Г. Пехименко);
-
Scaling Ensemble Distribution Distillation to Many Classes with Proxy Targets (Максим Рябинин, Андрей Малинин, М. Гейлс);
-
Revisiting Deep Learning Models for Tabular Data (Ю. Горишный, Иван Рубачев, В. Хрульков, Артем Бабенко);
-
Good Classification Measures and How to Find Them (М. Гёсгенс, А. Жиянов, А. Тихонов, Людмила Прохоренкова).
Мы попросили нескольких авторов рассказать о своих статьях:
Центр глубинного обучения и байесовских методов: Заместитель заведующего центром
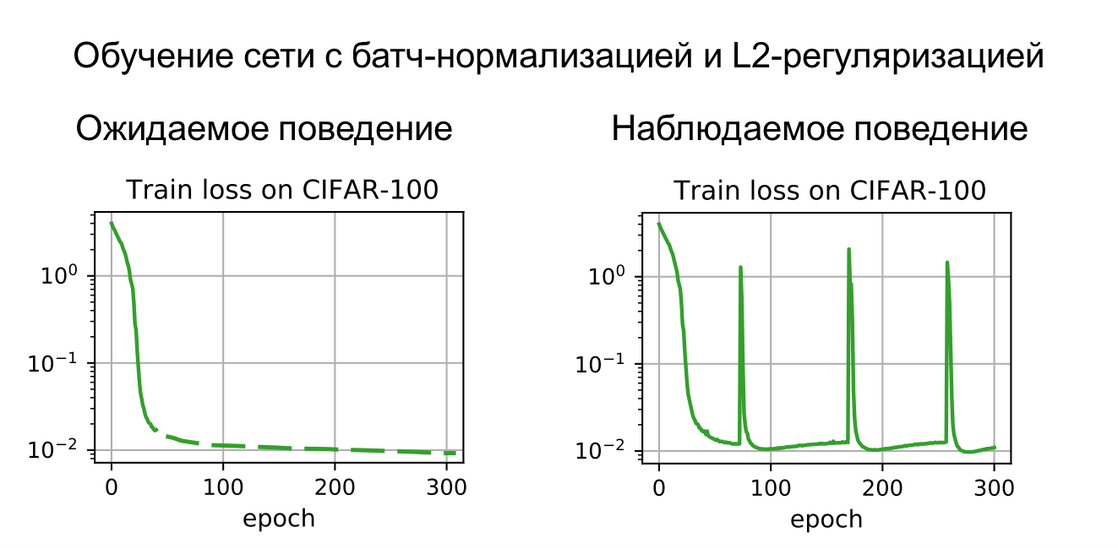
При обучении современных нейронных сетей нужно учитывать множество тонкостей, которые связаны как со структурой самих сетей, так и с методами их обучения. В нашей статье On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay мы исследуем необычное поведение сетей с одновременным использованием слоев нормализации и L2-регуляризацией весов при обучении. Это два очень распространенных приема, использующиеся практически во всех современных нейронных сетях, поэтому понимание особенностей их взаимодействия важно для решения практических задач. Суть работы состоит в том, что при достаточно долгом обучении нейросети функция ошибки вместо монотонного снижения начинает вести себя периодически: периоды сходимости нейросети прерываются резкими развалами, после которых процесс обучения начинается практически заново. В нашей статье мы очень подробно исследуем причины такого поведения, а также показываем, в каких ситуациях оно может встречаться.
Научно-учебная лаборатория компании Яндекс: Младший научный сотрудник
В этой статье мы предложили практический подход для распределённого обучения нейросетей, в котором могут участвовать добровольцы со всего мира. Данный подход набирает всё большую актуальность в последнее время: объём вычислений, необходимый для самых больших моделей, зачастую требует доступа к дорогим суперкомпьютерам, а он есть не у каждого желающего. С учётом того, что такие модели порой не оказываются в открытом доступе, сложности с воспроизведением результатов исследований негативно сказывается на научном прогрессе в машинном обучении.
Предложенный в работе метод под названием Distributed Deep Learning in Open Collaborations (DeDLOC) позволяет эффективно агрегировать результаты распределённого обучения даже в ситуации сравнительно медленного соединения и нестабильного участия узлов: нереалистично ожидать, что компьютер каждого участника обладает гигабитным подключением и будет подключен к сети 24/7. Пожалуй, один из самых интересных результатов работы — успешный эксперимент по обучению модели представлений для бенгальского языка с участием 40 настоящих добровольцев. Совместно с ними мы получили нейросеть, качество понимания языка которой сравнимо с самыми мощными кросс-языковыми моделями, обученными на кластере в сотни видеокарт.
Международная лаборатория стохастических алгоритмов и анализа многомерных данных: Заведующий лабораторией
Многие популярные алгоритмы машинного обучения, такие как стохастический градиентный спуск в задаче регрессии, на самом деле представляют собой алгоритмы стохастической аппроксимации. В подобных алгоритмах мы пытаемся найти нули некоторой функции, вместо значений которой имеется доступ лишь к случайным величинам, являющимися несмещенными оценками значений данной функци. В своей статье мы рассмотрели случай линейной стохастической аппроксимации (LSA), приближающей решение системы линейных уравнений, основываясь на случайных реализациях матрицы системы и ее правой части.
Нам удалось получить оценки на ошибку линейной стохастической аппроксимации при более слабых предположениях, чем были известны в литературе. Мы впервые показали, что при таких предположениях возможна только полиномиальная концентрация для ошибки на n-м шаге LSA, причем ее порядок зависит от шага алгоритма. Примеры, приведенные в нашей статье, показывают, что данный результат не может быть улучшен без дополнительных предположений на поведение наблюдаемых случайных матриц. Это показывает, что оценки, полученные с помощью процедуры линейной стохастической аппроксимации, вообще говоря, отличаются тяжелыми хвостами. Похожее поведение также типично для итераций стохастического градиентного спуска.
{kind=link}
{kind=link}