- A
- A
- A
- АБB
- АБB
- АБB
- А
- А
- А
- А
- А
Адрес: 109028, г. Москва, Покровский бульвар, д. 11, корпус S, комната S938 (станции метро "Чистые пруды" и "Курская").
Телефон: +7(495) 772-95-90 *27319



Департамент анализа данных и искусственного интеллекта был создан в 2014 году на базе кафедры анализа данных и искусственного интеллекта. В его состав входят исследователи с мировым именем, активно участвующие в международных исследовательских проектах.
Acquaye F. L., Kertesz-Farkas A., Stafford Noble W.
Journal of Proteome Research. 2023. Vol. 22. No. 2. P. 577-584.
Vasilii A. Gromov, Yury N. Beschastnov, Korney K. Tomashchuk.
PeerJ Computer Science. 2023. Vol. 9. No. .
Kanovich M., Kuznetsov S., Scedrov A.
Information and Computation. 2022. Vol. 287.
Egurnov D., Ignatov D. I.
Automation and Remote Control. 2022. Vol. 83. No. 6. P. 894-902.
Egurnov D., Точилкин Д. С., Ignatov D. I.
In bk.: Complex Data Analytics with Formal Concept Analysis. Springer, 2022. P. 239-258.
Dudyrev F., Neznanov A., Anisimova K.
In bk.: Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners’ and Doctoral Consortium -23rd International Conference, AIED 2022, Durham, UK, July 27–31, 2022, Proceedings, Part II. Springer, 2022. P. 436-439.
Zhirayr Hayrapetyan, Nascimento S., Trevor F. et al.
In bk.: Information Systems and Technologies: WorldCIST 2022, Volume 2. Iss. 469. Springer, 2022. P. 141-147.
Dudyrev E., Semenkov Ilia, Kuznetsov S. et al.
Plos One. 2022. Vol. 17. No. 10.

Вышел в печать авторский учебник Б.Г. Миркина «Введение в анализ данных»

Аннотация
Анализ данных — предмет, порожденный компьютерной революцией, приведшей к накоплению огромного количества конкретных данных о совокупностях объектов, таких как страны или регионы, веб-сайты, работодатели и работники, товары и продавцы. В отличие от классической математической статистики анализ данных не пытается вывести свойства окружающего мира исходя из специально собранных данных, а ориентирован на отыскание каких-либо паттернов, закономерностей, структуры в имеющихся данных.
В данном учебнике, подготовленном на основе большого международного опыта исследований и преподавания, излагаются основные методы анализа данных, относящихся прежде всего к одному или двум изучаемым признакам. Подробно рассмотрены вопросы анализа и интерпретации связей между двумя количественными, двумя качественными, а также качественным и количественным признаками. Из многомерных методов рассмотрены наивный Бэйесовский классификатор и метод K-средних для кластерного анализа, включая «интеллектуальную» версию с автоматическим определением числа кластеров и их начального местоположения. Изложение ориентировано на людей, предпочитающих не формулы, а вычисления, и содержит большое количество иллюстративных примеров применения рассматриваемых понятий к анализу реальных данных.
Для студентов бакалавриата и магистратуры инженерно-технических специальностей, также может использоваться для самостоятельного изучения.
Демонстрационный файл (PDF, 432 Кб)
Учебник соответствует Федеральному государственному образовательному стандарту высшего образования четвертого поколения.
Учебник и практикум Б.Г. Миркина «Введение в анализ данных», 2014, Юрайт, Москва, 174 стр. – один из многих десятков учебников, появившихся в результате совместных усилий НИУ ВШЭ и издательства Юрайт (г. Москва). Однако он сильно выделяется из общей массы. Именно этот учебник был выбран редакцией в качестве «Учебника года», и можно понять почему. Книга представляет собой серьёзно доработанный и осовремененный вариант двух с половиной глав из более раннего учебника Б.Г. Миркина «Коренные понятия анализа данных: суммаризация, корреляция и визуализация (Coreconceptsindataanalysis: summarization, correlationandvisualization)», изданного международным издательством Шпрингер на английском языке в 2011 году. Этот же учебник послужил основой курса лекций https://www.coursera.org/course/datan
проведённого Б.Г. Миркиным на международном портале Курсера в 2014 году. Курсы проф. Миркина являются базовыми в бакалавриате и магистратуре по направлению "Прикладная математика и информатика".
Процитируем несколько международных отзывов:
Core concepts in data analysis is clean and devoid of any fuzziness. The author presents his theses with a refreshing clarity seldom seen in a text of this sophistication. The entire text is rich in solved examples, case studies, projects, and introspective questions. … To single out just one of the text’s many successes: I doubt readers will ever encounter again such a detailed and excellent treatment of correlation concepts. Although this book is in Springer’s “Undergraduate Topics in Computer Science” series, statisticians will also find it refreshing and engaging. (Из Computing Reviews of ACM, 2011)
Pity I chose the wrong set of courses to get started with my data science learning... discovered this course too late (just today). I simply loved the week 1 videos, and Prof. Mirkin's approach in general. Thanks! (Anonymous 2014, Coursera)
Thank for you a great course. I enjoyed learning new ways to approach some problems that I thought I understood and new skills. I liked that you did not treat all topics like a survey course but instead you went into some depth with the topics. (Craig Milhiser, 11 June 2014, Coursera)
I greatly appreciate Professor Boris Mirkin's course. He is very insightful and the choice of topics and the presentations are superb. His presentation is often from an unique perspective different from ordinary textbook presentation of the same topics. (Philip Law, 20 June 2014, Coursera)
This is one of the best (if not the best) courses I've taken so far. Lectures are interesting and some advanced material not mentioned in many textbooks is covered. (Krsto Prorokovic, 24 June 2014, Coursera)
Эти отзывы вызвали у меня и моих коллег вопросы, на которые я попросил ответить самого автора:
И.М.: Я так понимаю, что учебник – авторский и отражает именно Ваше – нетрадиционное – видение предмета. Чем же оно отличается?
Б.М.: До недавнего времени было принято к любым данным относиться как к сгенерированным каким-то случайным механизмом, параметры которого постоянны. Главная задача при этом – использовать наблюдённые данные для выводов об именно этих предполагаемых, модельных параметрах. Это – взгляд так называемой математической статистики, который далеко не устарел. Но он просто не справляется с современной ситуацией, когда данных так много и они настолько разнообразны, что на первый план выходят значительно более «мягкие» задачи: какого рода связи или паттерны можно увидеть в данных, не предполагая, что данные порождены вероятностным механизмом. Оказывается, и в этих условиях можно использовать многие концепции математической статистики, но здесь они получают совсем другой смысл.
И.М.: Звучит хотя и интригующе, но как-то уж очень абстрактно. Нельзя ли конкретизировать? Скажем, какой-нибудь пример корреляционных построений, о которых с таким восхищением говорит рецензент Всемирной ассоциации вычислительных машин?
Б.М.: Рассмотрим таблицу сопряжённости, показывающую распределение компьютерной грамотности по регионам мира среди 7 миллиардов населения планеты (Табл. 1).
|
World Regions |
Internetusers, mln |
Non-users, mln |
Population, |
|
168 |
932 |
1100 | |
|
1077 |
2823 |
3900 | |
|
518 |
302 |
820 | |
|
90 |
135 |
225 | |
|
274 |
76 |
350 | |
|
255 |
345 |
600 | |
|
24 |
12 |
36 | |
|
2406 |
4625 |
7031 | |
|
From http://www.internetworldstats.com/stats.htm |
|
|
|
Таблица 1. Большие данные о компьютерной грамотности населения в разрезе регионов планеты сведены в таблицу сопряжённости.
Таблица как таблица, скажете Вы – ничего особенного. И будете правы. Но посмотрим на итог – 2.4 млрд компьютерно-грамотных из 7 млрд – это чуть больше одной трети всего населения планеты. Теперь обратим внимание, что в Океании/Австралии соотношение противоположно – две трети компьютерно-грамотных, то есть в этом регионе компьютерно-грамотных примерно на 100% больше, чем в среднем на планете. Любопытно, скажете Вы – и что же? А то, что эта относительная величина – я называю её по имени первооткрывателя (1842 г.) коэффициентом Кетле, – позволяет автоматически вскрывать существенные отклонения от средних характеристик на всем поле таблицы. Более того, усредняя коэффициенты Кетле по всей таблице, мы получим среднее относительное отклонение от среднего распределения распределений одного признака в категориях другого. Данная величина имеет чёткий смысл характеристики корреляции между двумя признаками, в данном случае, регион планеты и компьютерная грамотность. Оказывается, значение среднего коэффициента Кетле всегда равно так называемому коэффициенту сопряжённости хи-квадрат Пирсона, наиболее популярной характеристике таблиц сопряжённости, введённой в 1901 г. для проверки статистических гипотез о независимости признаков. В учебниках статистики по всему миру утверждается, что значение коэффициента Пирсона само по себе не имеет смысла вне гипотезы независимости, а в моем учебнике доказывается, что это не так. Коэффициент Пирсона равен коэффициенту Кетле, что придаёт ему смысл характеристики связи признаков, так что он может использоваться для автоматизации анализа больших данных о категориальных признаках.
И.М.: Может ли материал учебника быть доступен читателям – не математикам?
Б.М.: Да, конечно. Во введении я специально подчёркиваю, что учебник ориентирован на читателя, «который не любит формул, но не прочь посчитать». Это, прежде всего, студенты и специалисты в области программной инженерии, прикладной математики, инженеры всех специальностей, экономисты, социологи.
И.М. Можно ли пытаться изучать материал самостоятельно?
Б.М. Да, конечно, кроме основного материала приводятся упражнения четырёх уровней сложности – рабочие примеры, задания, вопросы и проекты, как с подробными решениями, так и только с ответами. Помогают также связанные с материалом шутки (их приведено более 50) и забавные иллюстрации (см. рис.1 и 2). 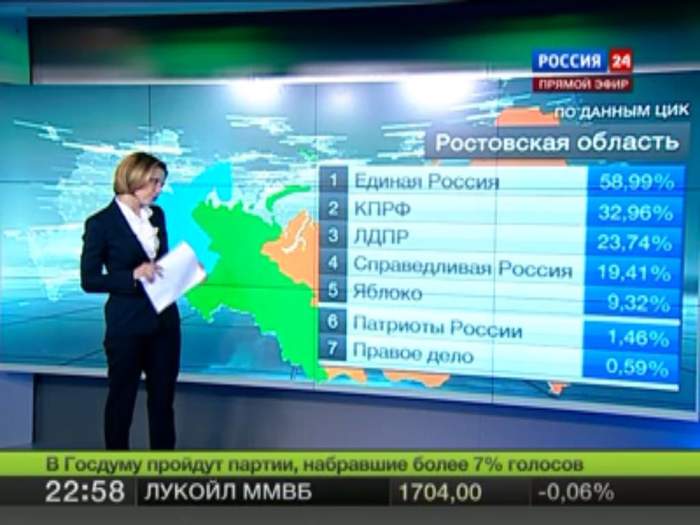
Рис. 1. Итоги голосования по партийному признаку должны суммироваться к 100% согласно принципу «один избиратель — один голос». Ведущая явно в замешательстве — в одной из областей это явно не так!
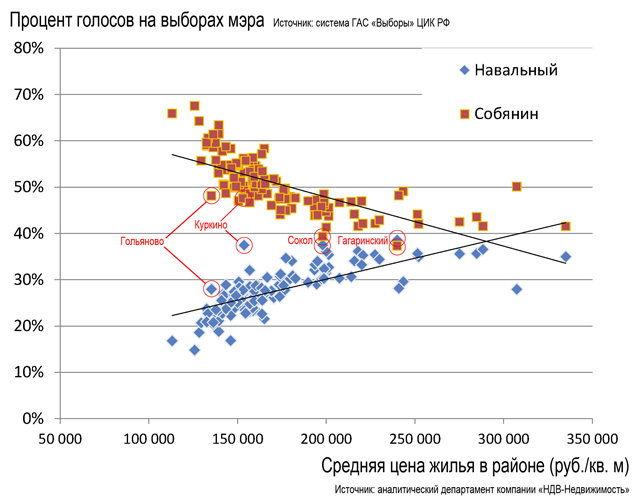
Рис.2. Поля рассеяния по результатам голосования за каждого из двух кандидатов на выборах в мэры в Москве (сентябрь 2013 г.)
Пример шутки, связанной с пространственно-временными данными, но имеющей, как кажется, и более широкий смысл: «Всероссийское радио начинает передачи и сообщает: — В Москве — 15 часов, в Свердловске — 16, в Томске — 17, в Иркутске — 18, во Владивостоке — 2З, в Петропавловске-Камчатском — полночь. Человек слушает, слушает и говорит: — Ну и бардак в стране!».
И.М. Как можно понять, учебник посвящён в основном методы анализа данных об одном или двух признаках. Как насчёт продолжения – учебника по методам анализа многомерных данных?
Б.М. Постараюсь. Материал есть.
Интервью провел зам. рук. департамента анализа данных и искусственного интеллекта, Макаров И.А.
Выражаем особую благодарность Борису Григорьевичу Миркину за познавательное и как всегда искрометное интервью.
Департамент анализа данных и искусственного интеллекта: заместитель руководителя
Все новости автора
Миркин Борис Григорьевич
Ординарный профессор НИУ ВШЭ