Faculty Submits Ten Papers to NeurIPS 2021
![]()
35th Conference on Neural Information Processing Systems (NeurIPS 2021) is one of the world's largest conferences on machine learning and neural networks. It takes place on December 6-14, 2021.
This year, NeurIPS has accepted ten papers by the researchers of the Faculty of Computer Science:
-
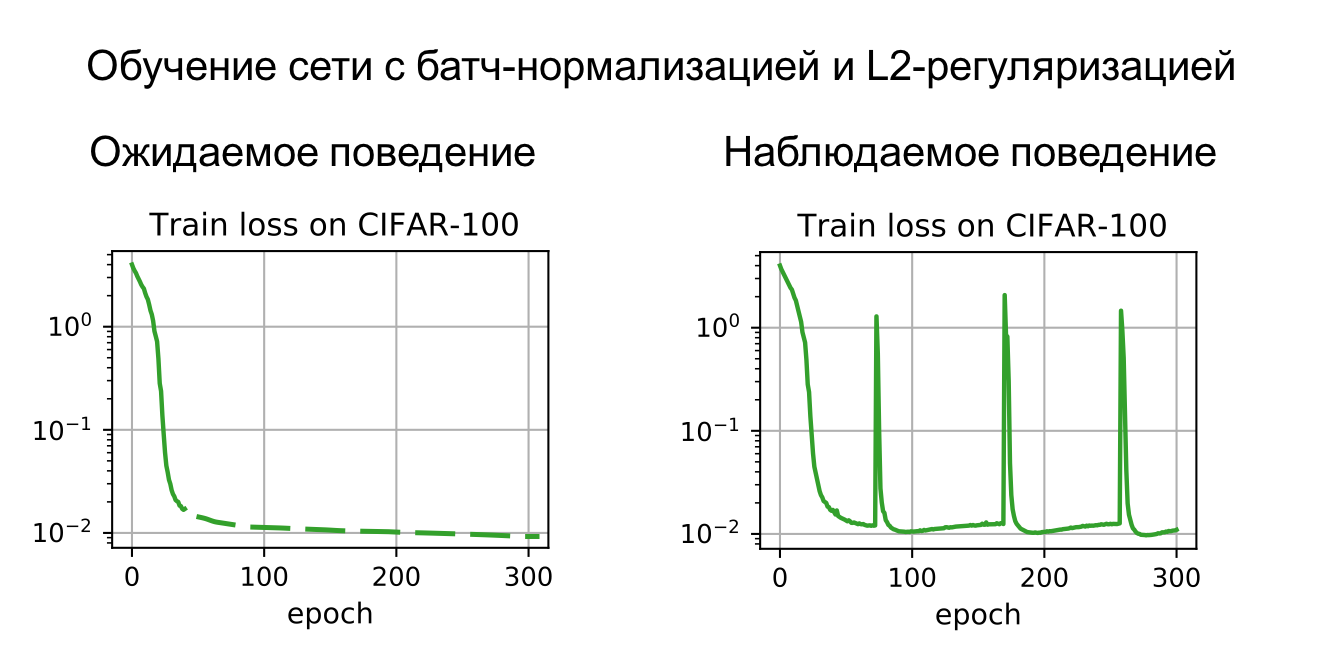
On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay (Ekaterina Lobacheva, Maxim Kodryan, Nadezhda Chirkova, Andrey Malinin, Dmitry Vetrov)
-
Leveraging Recursive Gumbel-Max Trick for Approximate Inference in Combinatorial Spaces (Kirill Struminsky, Artyom Gadetsky, Denis Rakitin, D. Karpushkin, Dmitry Vetrov)
-
Distributed Saddle-Point Problems Under Similarity (Aleksandr Beznosikov, G. Scutari, Alexander Rogozin, Alexander Gasnikov)
-
Lower Bounds and Optimal Algorithms for Smooth and Strongly Convex Decentralized Optimization Over Time-Varying Networks (D. Kovalev, E. Gasanov, P. Richtárik, Alexander Gasnikov)
-
Moshpit SGD: Communication-Efficient Decentralized Training on Heterogeneous Unreliable Devices (Max Ryabinin, Eduard Gorbunov, Vsevolod Plokhotnyuk, G. Pekhimenko)
-
Tight High Probability Bounds for Linear Stochastic Approximation with Fixed Stepsize (A. Durmus, Eric Moulines, Alexey Naumov, Sergey Samsonov, K. Scaman, H. Wai)
-
Distributed Deep Learning in Open Collaborations (Michael Diskin, A. Bukhtiyarov, Max Ryabinin, L. Saulnier, Q. Lhoest, Anton Sinitsin, Dmitry Popov, Dmitry Pyrkin, Maxim Kashirin, Alexander Borzunov, A. Villanova del Moral, D. Mazur, I. Kobelev, Y. Jernite, T. Wolf, G. Pekhimenko)
-
Scaling Ensemble Distribution Distillation to Many Classes with Proxy Targets (Max Ryabinin, Andrey Malinin, M. Gales)
-
Revisiting Deep Learning Models for Tabular Data (Y. Gorishniy, Ivan Rubachev, V. Khrulkov, Artem Babenko)
-
Good Classification Measures and How to Find Them (M. Gösgens, A. Zhiyanov, A. Tikhonov, Liudmila Prokhorenkova)
We asked some of the authors to tell us about their articles:
Correction
Ekaterina Lobacheva
Deputy Head of the Centre
When training modern neural networks, there are many details to consider, both in the structure of the networks themselves and in their training methods. In our article "On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay" we investigate the unusual behaviour of networks with simultaneous use of normalization layers and L2-regularization of weights in training. These are two very common techniques used in almost all modern neural networks, so understanding their interaction is important for solving practical problems. The essence of the work is that with long enough training of a neural network the error function instead of a monotonic decrease begins to behave periodically: periods of neural network convergence are interrupted by sharp decays, after which the learning process begins almost anew. In our article, we investigate in detail the reasons for such behaviour and show in which situations it can occur.
In this paper, we propose a practical approach for distributed neural network training, in which volunteers from all over the world can participate. This approach has become increasingly relevant recently: the amount of computation required for the largest models often requires access to expensive supercomputers, and not everyone has access to them. Given that such models are sometimes not in the public domain, the difficulty in reproducing the results of research negatively affects the scientific progress in machine learning.
The method proposed in the paper, called Distributed Deep Learning in Open Collaborations (DeDLOC), allows efficient aggregation of distributed learning results even in situations of relatively slow connectivity and unstable node participation: it is unrealistic to expect that each participant's computer has a gigabit connection and will be connected to the network 24/7. Perhaps one of the most interesting results of the work is the successful experiment to train a representational model for Bengali with 40 real volunteers. Together with them, we obtained a neural network whose language comprehension quality is comparable to the most powerful cross-language models trained on a cluster of hundreds of video cards.
Sergey Samsonov
Research Assistant
Many popular machine learning algorithms, such as stochastic gradient descent in a regression problem, are actually stochastic approximation algorithms. In such algorithms, we are trying to find the zeros of some function whose values only have access to random variables that are unbiased estimates of that function's values. In our paper, we considered the case of linear stochastic approximation (LSA) which approximates the solution of a system of linear equations based on random realizations of the system matrix and its right-hand side.
We have succeeded in obtaining estimates on the error of the linear stochastic approximation under weaker assumptions than have been known before. We have shown for the first time that under such assumptions only a polynomial concentration for the error at the nth step of the LSA is possible, with its order depending on the step of the algorithm. The examples in our paper show that this result cannot be improved without additional assumptions on the behaviour of the observed random matrices. This shows that the estimates obtained using the linear stochastic approximation procedure are, generally speaking, characterised by heavy tails. Similar behaviour is also typical for stochastic gradient descent iterations.
{kind=link}
{kind=link}
Among the authors of the NeurIPS 2021 articles are the students of the Faculty Vsevolod Plokhotnyuk, Anton Sinitsin, Dmitry Popov, Dmitry Pyrkin, and Maxim Kashirin.
Alexander Borzunov
Artyom Gadetsky
Aleksandr Gasnikov
Eduard Gorbunov
Maxim Kodryan
Ekaterina Lobacheva
Малинин Андрей Алексеевич
Liudmila Prokhorenkova
Alexander Rogozin
Nadezhda Chirkova